Importation des données
Ce paragraphe a pour but de détailler le traitement d’importation de données et de lister ses caractéristiques de fonctionnement.
Sur le principe, ce traitement ne dispose pas « d’intelligence » à proprement parler puisque il ne fait que lire le contenu de deux fichiers ayant été générés par le traitement d’exportation.
Un import comportera toujours deux phases :
Mise à jour des données dans la base
Génération des éléments importés (Requêtes DIALOG, Tables de valeurs, Liste paramétrées …)
Par défaut, ces deux phases s’enchainent automatiquement . Nous verrons qu’il est possible de les dissocier et de reporter la phase de génération dans un second temps
Critères
Permet de donner le contexte d’exécution au traitement
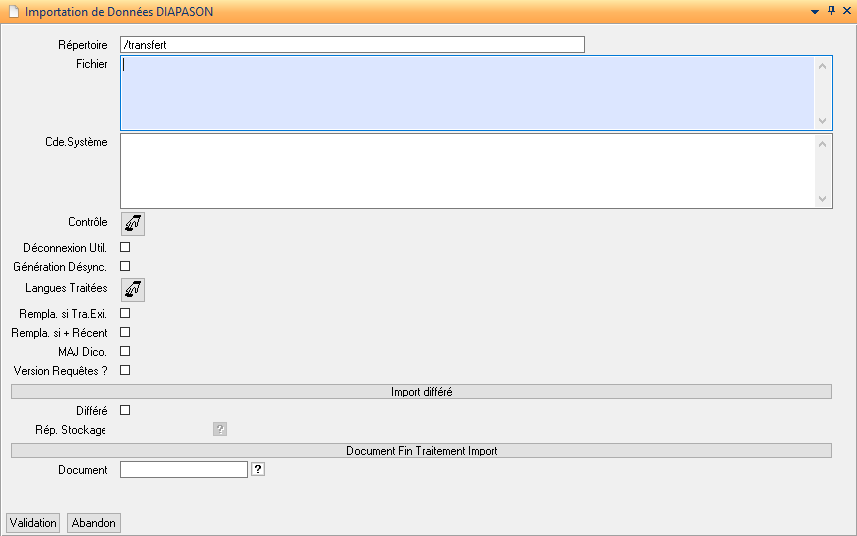
A minima, il faut renseigner le ou les fichiers contenant les données à importer. Les zones Répertoire et Fichier sont obligatoires. La zone Fichier dispose d’une aide permettant de lister les fichiers pris en charge et se trouvant dans le répertoire donné au préalable. Il est possible de renseigner plusieurs fichiers sous la forme d’une liste dont le séparateur est la « , » (virgule). L’aide sur cette zone est cumulative, chaque fois qu’un fichier est sélectionnée, la zone Fichier est automatiquement mise à jour en ajoutant le fichier sélectionné avec le séparateur « , ».
Traitement d’importation avec n fichiers
Le traitement peut traiter un paquet de plusieurs fichiers. Ces fichiers sont traités dans l’ordre donné par la liste chainée sur la zone « Fichier ».
La notion d’ordre est importante puisque si des objets communs sont contenus dans plusieurs fichiers d’un même paquet, c’est le dernier traité qui fera foi.
Afin d’optimiser les temps du traitement, une gestion de doublons est en place pour ne traiter qu’une seule fois les éléments communs.
Méthodes d’importation des donnéés
Méthode standard (ou méthode 0)
Cette méthode est présente depuis l’origine de DIAPASON. Elle reste active et compatible au fur et à mesure des montées de versions de DIAPASON.
Les fichiers sont organisés par objet, un objet est un ensemble de données réparti dans 1 ou plusieurs tables.
De part le jeu des liens entre objets, on retrouve les données dispatchées dans plusieurs endroits du fichier de données.
La mise à jour des données en base se fait donc par de multiples accès aux tables au fur et à mesure de la lecture des fichiers.
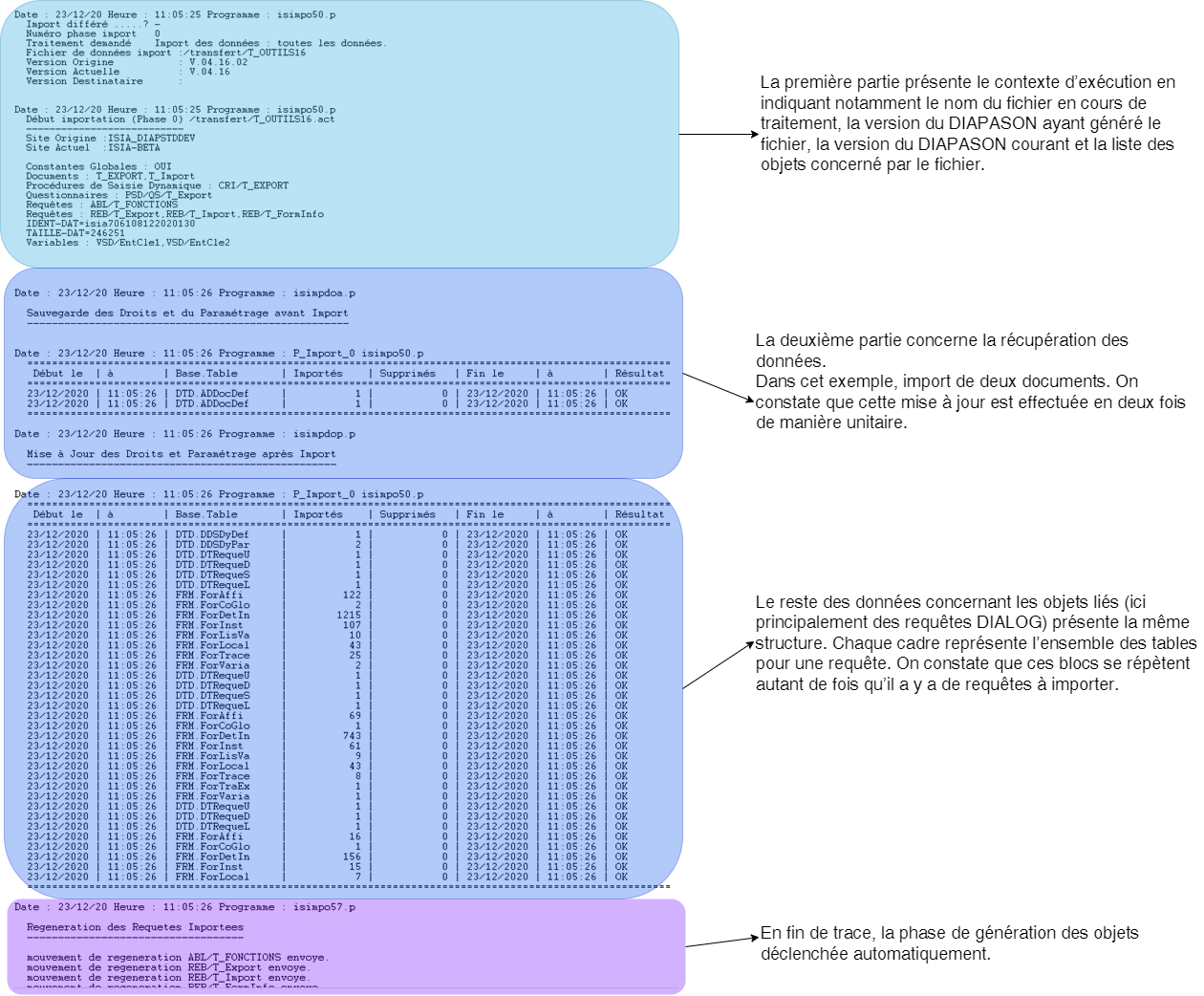
Le fichier trace reflète cette mise à jour :
Méthode optimisée (ou méthode 1)
Les fichiers sont organisés par table, ainsi, quels que soient les objets traités, chaque action de récupération de données traite une table dans sa globalité. Ceci a pour effet de limiter considérablement les accès pour les mises à jour et réduit considérablement le volume du fichier trace (moins d’accès en écriture).
Le fichier trace reflète cette mise à jour :
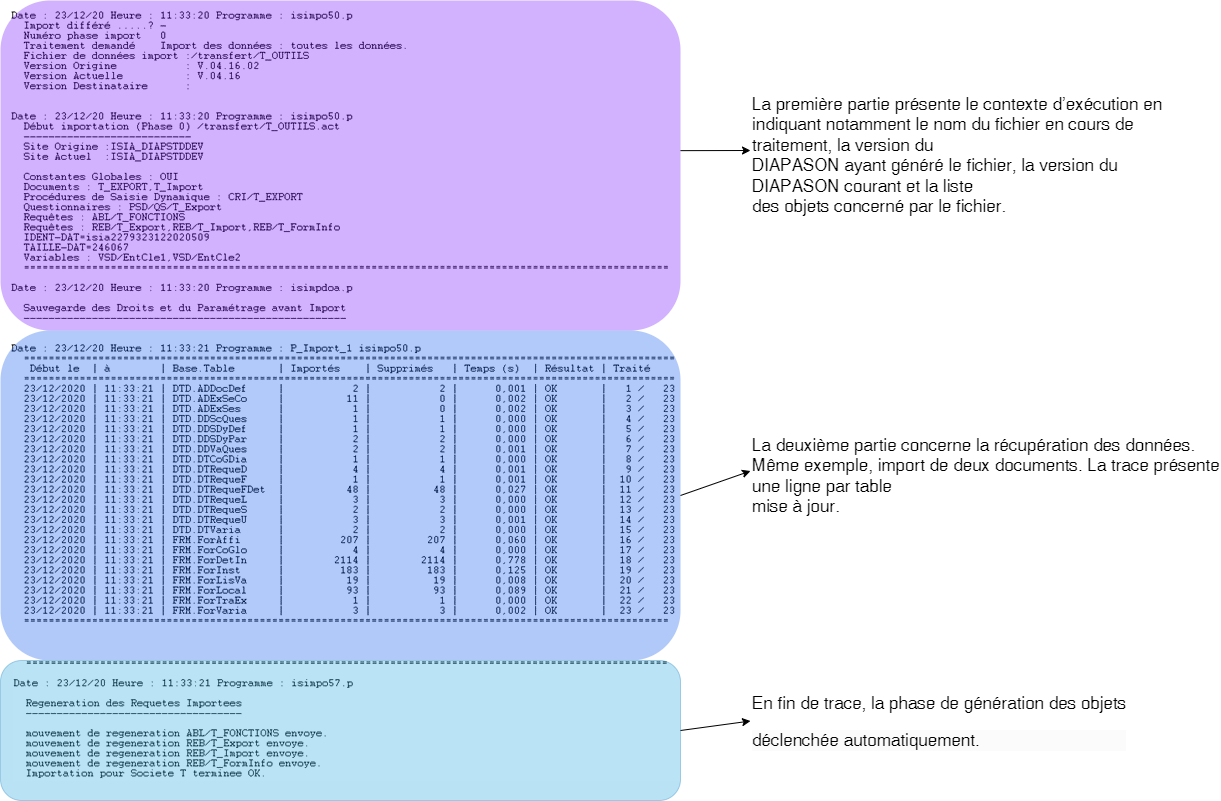
La trace du traitement présente une ligne par table avec pour chacune :
Importés : nombre d’enregistrements créés
Supprimés : nombre d’enregistrements supprimés
Temps (s) : temps en secondes de traitement de suppression et création pour la table
Résultat : OK ou ERREUR suivi du libellé erreur
Traité : avancement par table en fonction du nombre total de tables.
Importation en mode Différé
Le temps de traitement d’importation de données peut être très long en fonction du nombre de données à rapatrier. Les données les plus coûteuses en temps sont celles relatives aux requêtes DIALOG.
Cette évolution va permettre d’effectuer l’importation de données en deux phases . ce mode de traitement est appelé « Import différé ». Les phases sont :
Phase 1 : Import des données des requêtes uniquement. Les requêtes importées sont figées et ne sont pas modifiables (la génération des requêtes n’a pas eu lieu).
Phase 2 : Import des données autres que les requêtes (traitées en Phase 1) et postage des mouvements de génération.
Ce chapitre décrit ce mode de traitement d’importation.
Répertoires de stockage
De manière générale, les fichiers d’importation de données sont situés dans des répertoires temporaires (purgés à fréquence courte), or, dans le cadre de l’import différé il est indispensable de garder ces fichiers (nécessaires pour la phase 2).
Pour cela, il est indispensable de définir des répertoires physiques destinés à sauvegarder les fichiers et de les renseigner dans DIAPASON depuis la nouvelle application « Paramètres Importation » > « Répertoires de stockage »
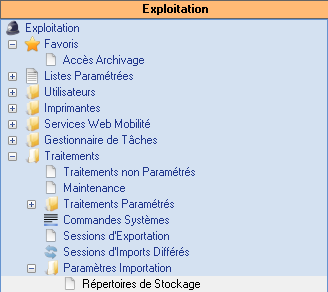
Sans ce paramétrage l’importation différé ne sera pas possible.
Le répertoire est defini comme suit :
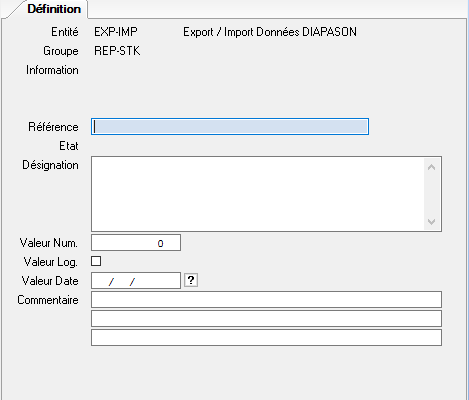
Référence : Zone obligatoire. Code interne DIAPASON du répertoire
Désignation : Zone obligatoire. Contient le chemin complet du répertoire physique sur le serveur
Fiche critère
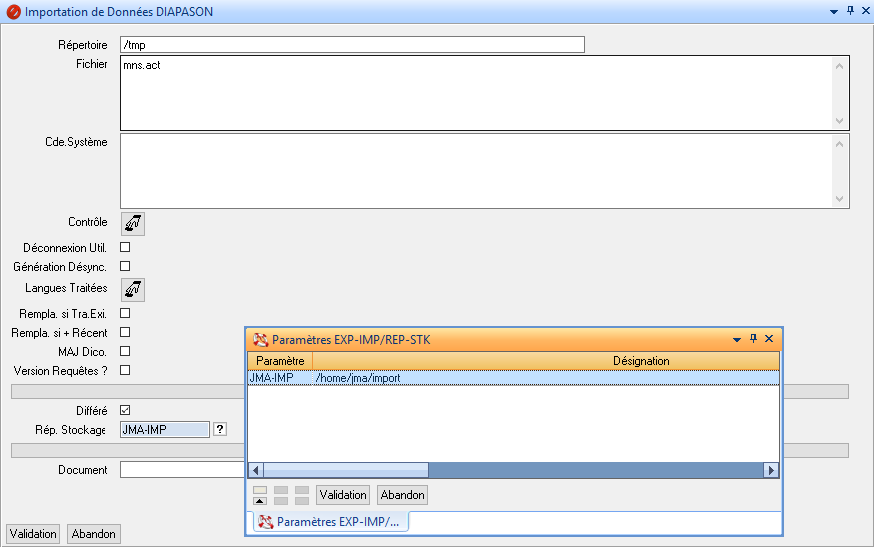
La section Import différé permet de forcer ce mode de traitement. Si le champ Différé est coché, la zone Rép. Stockage devient saisissable et obligatoire. Il faut y saisir une référence de répertoire de stockage parmi ceux référencés dans DIAPASON (une aide est disponible sur la zone).
Déroulement du traitement d’import par phase
L’exemple donné porte sur une session contenant deux documents et une requête.

Les fichiers d’export sont /tmp/impdiffere.act et /tmp/impdiffere.dat.
Phase 1
Lancement du traitement d’importation en mode différé :
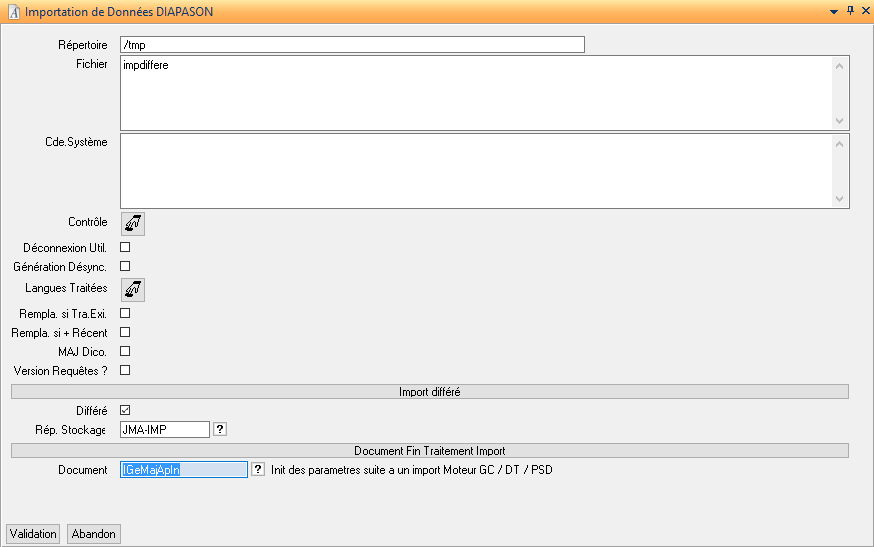
Le critère indique que l’import différé est demandé, le stockage des fichiers se fera dans JMA-IMP, un document après import doit s’exécuter (voir Exécution document en fin de traitement d’import).
La trace du traitement d’importation présente les informations suivantes :
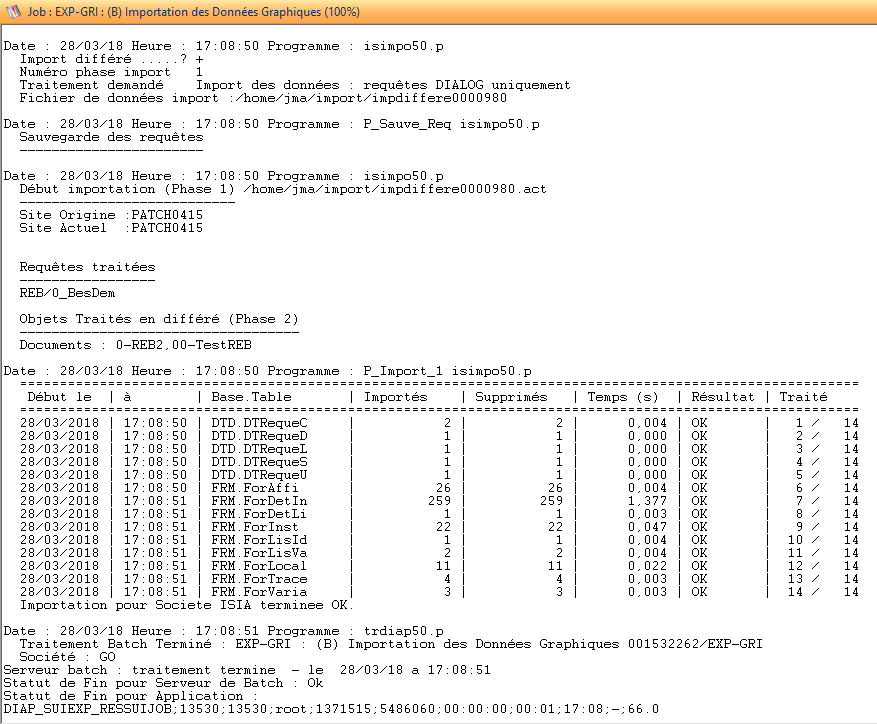
Les informations en début de trace détaillent le contexte d’exécution de l’import. Ici, phase 1, traitement des requêtes uniquement (sans postage des mouvements de génération).
La trace liste les éléments traités (Phase 1) et ceux traités en différé (Phase 2).
La requête REB/0_BesDem est bloquée car n’a pas été générée, c’est la phase 2 qui aura en charge d’effectuer cette opération. Dans cet état, la requête n’est pas accessible en saisie.

Enfin, le traitement d’import a automatiquement généré une session d’importation à partir de laquelle il est possible d’effectuer la phase 2.
Phase 2
Un nouvel environnement de sessions d’importation permet d’effectuer cette phase.
Il est accessible depuis

Cette application présente la liste des sessions d’import différé générées par la phase 1 du traitement d’importation.

Date
Date de création de la session. Correspond à la date d’exécution de la phase 1.
Heure
Heure de création de la session.
Session
Identifiant de la session.
Doc. Fin Trt.
Référence du document à exécuter en fin de traitement d’import.
Emplacement
Chemin complet du répertoire de stockage.
Fichiers
Noms des fichiers constituant le paquet d’importation
Site Origine
Identifiant du site à partir duquel les fichiers ont été générés.
Utilisateur
Référence utilisateur ayant lancé le traitement d’importation en mode différé.
Fichiers
La valeur cochée de ce drapeau rend compte de l’existence des fichiers dans le répertoire de stockage. Dans le cas où cette colonne est non cochée, la phase 2 ne pourra pas être accomplie.
Terminée ?
Indique si la session est terminée. Une session est automatiquement terminée après l’exécution de la phase 2 (finalisation de l’import). Elle peut aussi être forcée au statut « terminée » manuellement.
Annulée ?
Indique si la session a été annulée par l’utilisateur. Cette action n’est disponible que si la session n’est pas terminée.
Information
Libellé complémentaire sur l’absence des fichiers.
Les actions disponibles sur cette liste sont :
Contenu session

Liste présentant les objets composant le paquet à importer.
Contrôle des données
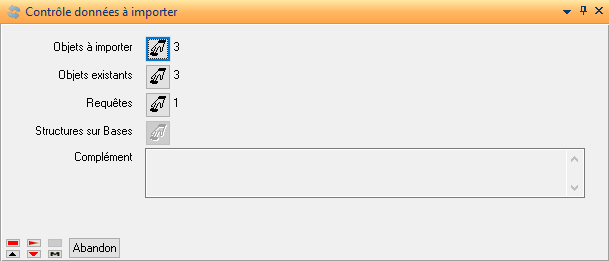
Lance la fonction de contrôle . Cette fonctionnalité est identique à celle déjà présente sur la fiche critère du traitement d’importation.
Lancement import
Cette action permet d’effectuer le traitement de la phase 2 de l’importation.
Lance le traitement d’importation de données sans saisie de critères. Ces derniers sont automatiquement initialisés à partir des données de la session d’import différé.
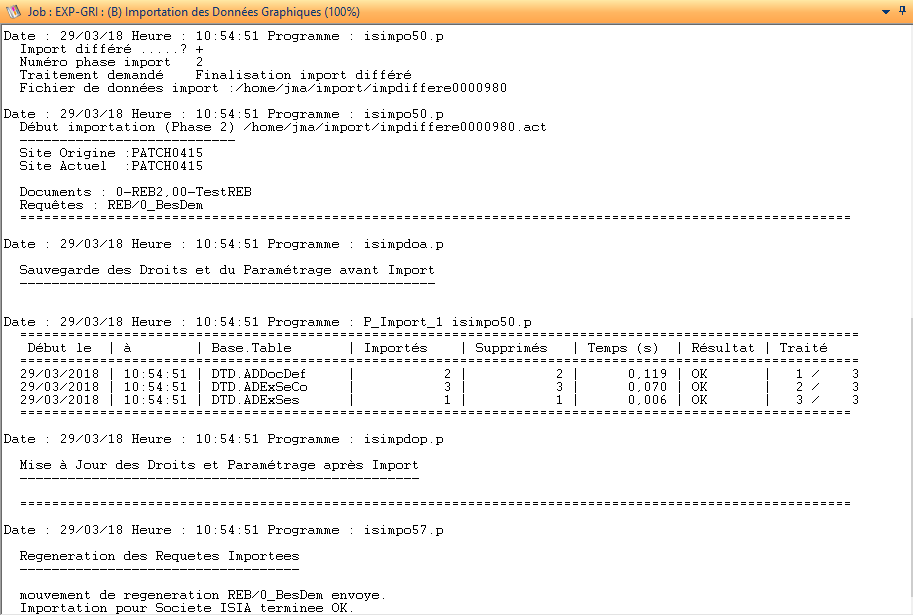
La trace du traitement précise que l’import est en mode différé , le numéro de phase est 2 et indique le fichier (ou les fichiers) traités.
Le tableau recense les tables importées. Les tables relatives aux requêtes DIALOG sont ignorées car traitées en phase 1.
Enfin, les mouvements de génération des requêtes sont postés.
A ce stade, les requêtes concernées par l’importation sont défigées .
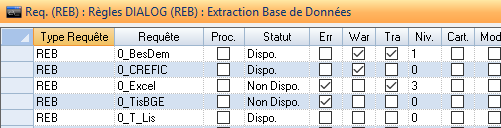
La session d’import différé est passée au statut « Terminée »

Session terminée
Cette action permet de forcer le statut « Terminée » sur la session courante. Une des raisons pouvant justifier cette action serait que le même paquet ait été importé en mode normal entre le moment de la phase 1 et le lancement de la phase 2.
Annulation Import
Cette action a pour effet de revenir en arrière afin de retrouver l’état d’origine des données avant le traitement de la phase 1. Ceci concerne exclusivement les données relatives aux requêtes DIALOG.
Sur le principe, une photo des données des requêtes DIALOG impactées par l’import est effectuée sous forme de fichiers stockés dans le répertoire de stockage (fichier .acs et .das).
Cette action bénéficie d’une phase de confirmation.
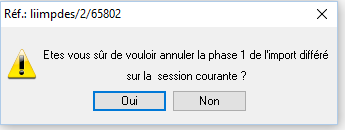
Le fait de confirmer lance le traitement d’importation de données , sans saisie de critères.
La trace présente les informations suivantes :
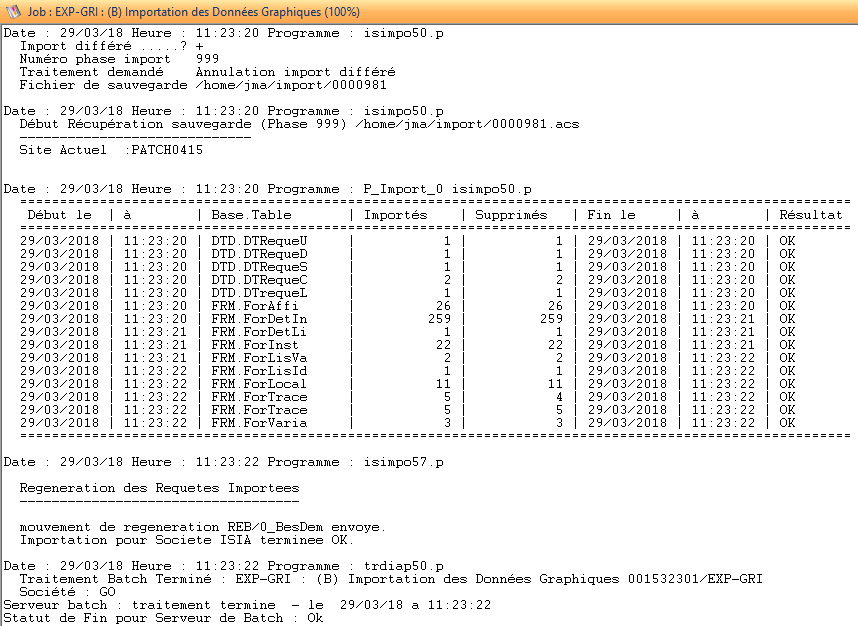
La trace du traitement précise que l’import est en mode différé , le numéro de phase est 999 et indique le fichier de sauvegarde traité.
Le tableau recense les tables importées. Seules les tables relatives aux requêtes DIALOG sont traitées.
Enfin, les mouvements de génération des requêtes sont postés.
Suppression
Cette action permet de supprimer une session terminée. La suppression concerne la session elle-même ainsi que les fichiers liés (stockés physiquement dans le répertoire de stockage de la session).
Cette action n’est disponible que sur les sessions dont le statut est « Terminée ».