Définition des règles d'identification
A quoi ça sert ?
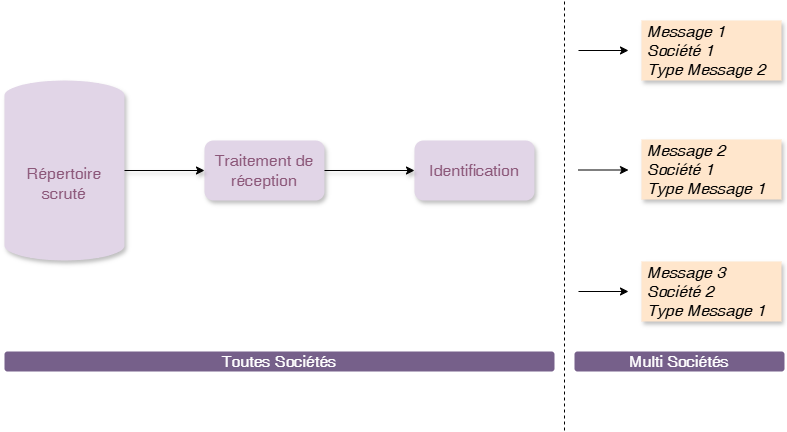
Quand un message entrant arrive dans DIAPASON, il va falloir que DIAPASON identifie de quel message il s’agit pour venir l’associer au type de message qui convient !
Pour un message XML, en général on va venir regarder quelle est la première balise du fichier pour pouvoir orienter vers le type de message qui va bien.
Dans le cadre de fichiers ascii, la condition pourra dépendre du contenu dont la localisation dans le fichier pourra être donnée selon une syntaxe précise.
Les règles d’identification sont définies pour toutes les sociétés.
Il existe deux types de règles d’identification de messages, accessibles par ici :
Règles d’Identification / XML
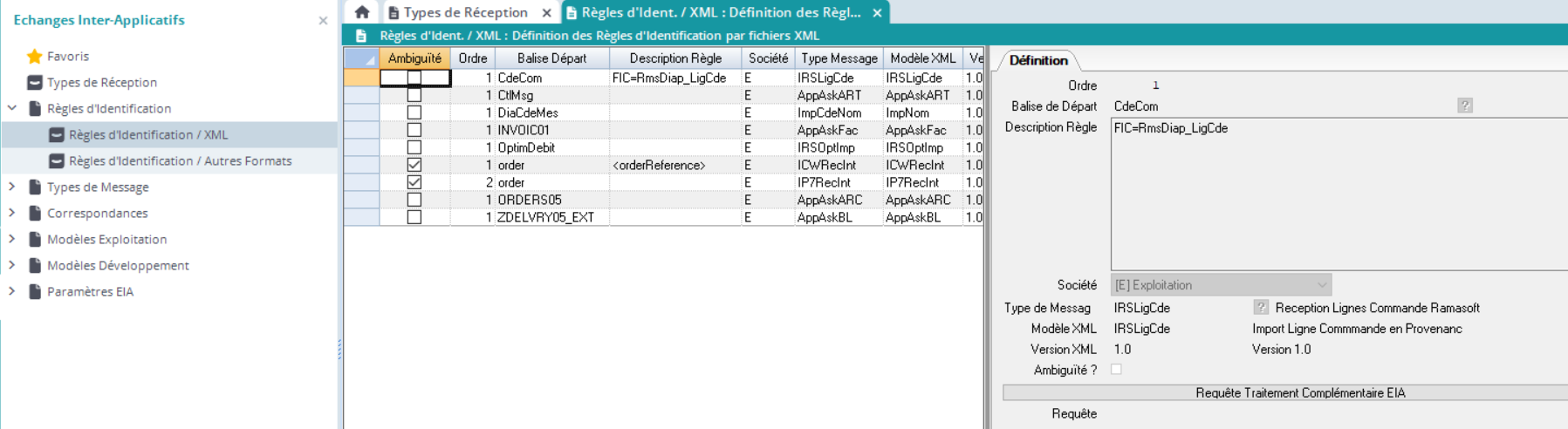
L’application de définition des règles d’identification / XML est accessible depuis l’explorateur et se présente sous la forme d’une GFG DIAPASON :
 |
La présence d’une ambiguïté n’est pas bloquante car le numéro d’ordre et la description de la règle peuvent permettre de lever l’ambiguïté. Cette information joue un rôle informatif avant tout. |
Quelles actions sont disponibles ?
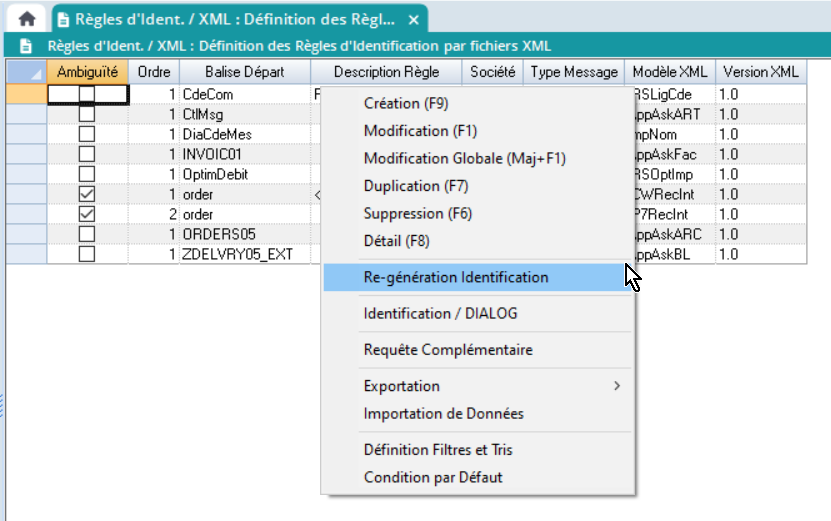
Régénération Identification Cette action a pour but de déterminer de façon automatique les règles d’identification possibles à partir de la base de modèles/version XML en exploitation et de la base des types de messages définis au moment de son lancement. Elle se présente sous la forme d’un tableur en saisie se présentant comme suit :
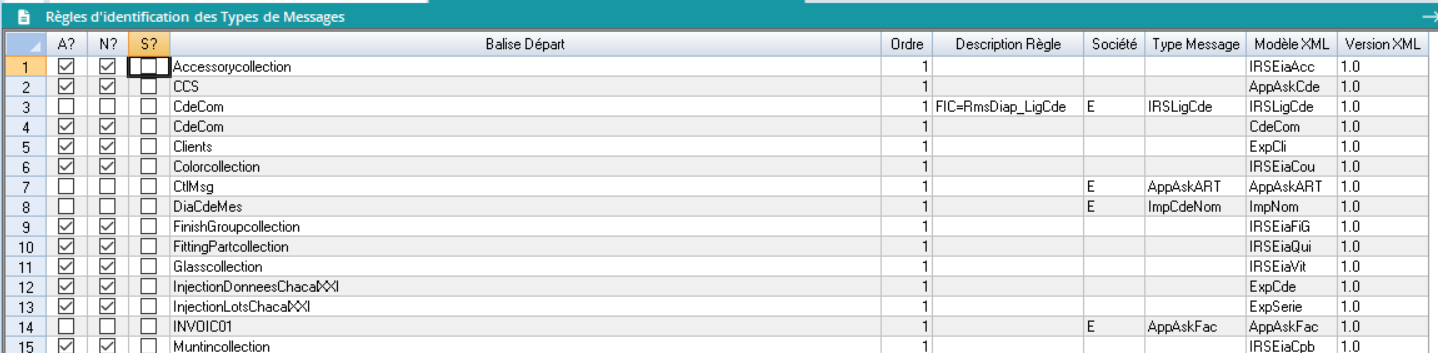 | Chaque ligne du tableur représente la définition d’une règle d’identification.
|
Identification / DIALOG Cette action permet de renseigner une requête décrivant les règles d’association message au couple société/type message. Cette règle d’identification est la seule ne raisonnant pas par la notion de balise de départ et est marquée par le caractère ‘*’ dans la référence balise de départ.Cette règle, si définie, est exécutée en fin de phase d’identification si aucune règle n’a pu déterminer d’association message / couple société/type message. Le contexte de cette règle est :
WFEIALisMes
SCR.EIA_FicRec
Il ne faut pas faire de CREATION LISTE WFEIALisMes dans cette requête.
Règles d’Identification / Autres Formats
Ce type de règle d’identification est dédié à l’association des messages entrants au format ascii et des couples société/type de message.
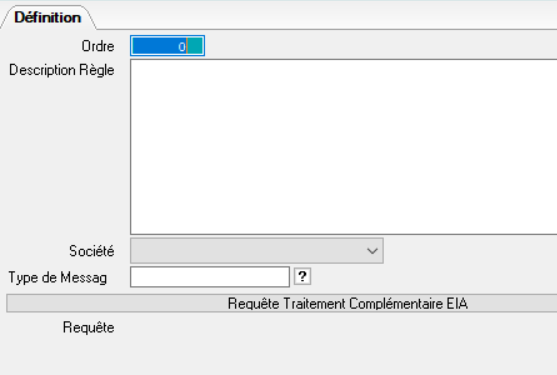 |
Description Règle Zone facultative permettant de décrire une règle par rapport à une valeur dans le contenu du fichier. Une syntaxe particulière permet de décrire l’emplacement (ligne, colonne) et la longueur de la chaîne de caractères à tester OU, dans le cadre d’un contenu de fichier sous forme de liste chaînée, de préciser la ligne, le numéro de mot et le caractère séparateur pour localiser la chaîne de caractères à tester. Il est aussi possible de raisonner à partir du nom du fichier.
|
Définition règle d’identification pour réception via messagerie
La réception de message via serveur de messagerie (type M0) impose une définition de règles d’identification particulière.
Les messages électroniques entrants issus de la scrutation d’une boite de messagerie via un type de réception « M0 » sont retranscris par DIAPASON sous la forme d’un message xml dont la structure est la suivante :

La règle d’identification portera obligatoirement sur la balise de départ « IS_MAIL ».
Deux solutions possibles pour le traitement du contenu d’un message électronique :
Les données sont directement inscrites dans le corps du message lui-même
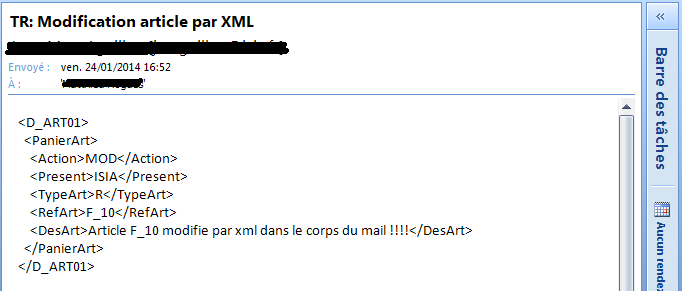
Ce type de message électronique peut être considéré comme un message xml simple car le corps décrit les données à traiter. DIAPASON génèrera un fichier xml sous la forme :
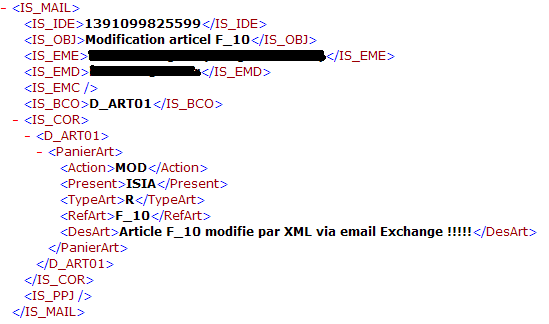
La règle d’identification peut tester la présence de la balise « D_ART01 » et aiguiller sur une type de message (« 0 » sur correspondances XML ou « 9 » décryptage complexe).
Les données sont inscrites dans une ou plusieurs pièces jointes du message
Ce type de message électronique sera considéré comme un message xml complexe car le fichier xml ressort uniquement les noms des fichiers effectivement à traiter (balise IS_CPJ dans le descripeur IS_PJ :
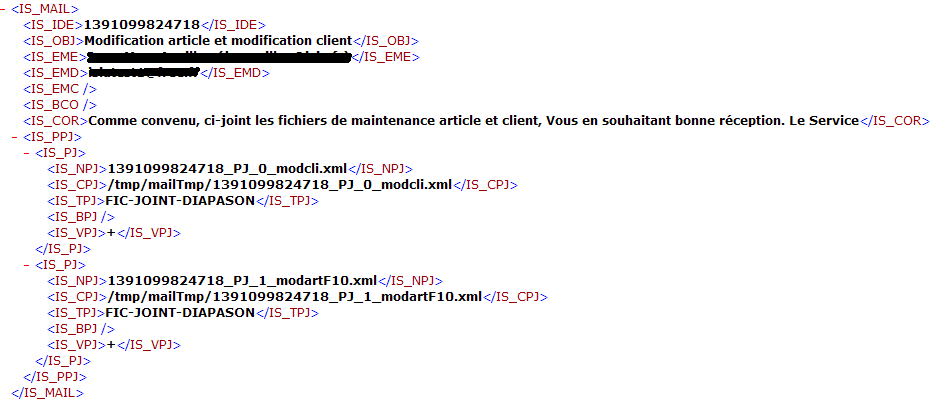
Note : dans tous les cas de figures il est conseillé de décrire une règle d’identification prioritaire (sur balise de départ IS_MAIL et testant la présence de la balise IS_PJ) destinée au traitement de messages électroniques avec pièces jointes. Cette règle devra faire l’association avec un type de message associé à la méthode de traitement « 9 » (décryptage complexe) .
Les règles d’identification sur des messages électroniques dont le corps contient les données à traiter peuvent faire l’objet de règles d’identification sur des types de messages associés aux méthodes de traitement « 0 » (par correspondance XML) ou « 9 » (décryptage complexe). Elles seront définies APRES la règle concernant les messages avec pièces jointes.